Indexes area unit wont to speed-up question method in SQL Server, leading to high
performance. They’re just like textbook indexes. In
textbooks, if you wish to travel to a selected chapter, you visit the index; notice the number of the chapter and
go on to that
page. While not indexes, the method of finding your required chapter would are terribly slow.
The same
applies to indexes in databases. While
not indexes, software should undergo all the records within the table so as to retrieve the required results. This method is termed table-scanning and is extraordinarily slow. On the opposite hand, if you produce indexes, the info goes thereto index initial and so retrieves the corresponding table records directly.
There area unit 2 varieties of Indexes
in SQL Server:
- Clustered Index
- Non-Clustered Index
Clustered Index:
A clustered index defines the order within which knowledge is physically keep in a very table. Table knowledge is sorted in just manner, therefore, there is just one clustered index per table. In SQL Server, the first key constraint mechanically creates a clustered index thereon explicit column.
Let’s take a glance. First, produce a “student” table within “schooldb” by execution the subsequent script, or make sure that your info is totally secured if you’re victimization your live data:
CREATE DATABASE schooldb
CREATE TABLE student
(
id INT PRIMARY KEY,
name VARCHAR(50) NOT NULL,
gender VARCHAR(50) NOT NULL,
DOB datetime NOT NULL,
total_score INT NOT NULL,
city VARCHAR(50) NOT NULL
)
Notice here within the “student” table we’ve got set primary key constraint on the “id” column. This mechanically creates a clustered index on the “id” column. To examine all the indexes on a selected table execute “sp_helpindex” keep procedure. This keep procedure accepts the name of the table as a parameter and retrieves all the indexes of the table. the subsequent question retrieves the indexes created on student table.
USE schooldb
EXECUTE sp_helpindex student
The higher than question can come back this result:
| Index Name | Index Description | Index Keys |
| PK__student__3213E83F7F60ED59 |
clustered, unique, primary key located on PRIMARY |
id |
In the output you’ll be able to see the sole one index. This can be the index that was mechanically created thanks to the first key constraint on the “id” column.
Another way to look at table indexes is by planning to “Object Explorer-> Databases-> Database_Name-> Tables-> Table_Name -> Indexes”. Investigate the subsequent screenshot for reference.
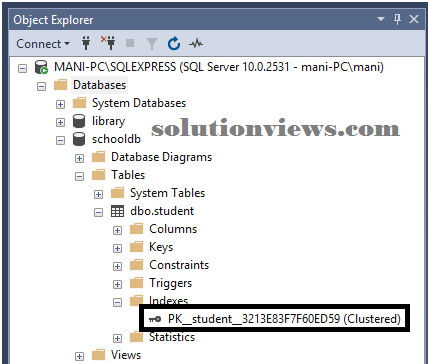
This clustered index stores the record within the student table within the ascending order of the “id”. Therefore, if the inserted record has the id of five, the record is inserted within the fifth row of the table rather than the primary row. Similarly, if the fourth record has Associate in nursing id of three, it’ll be inserted within the third row rather than the fourth row. This can be as a result of the clustered index should maintain the physical order of the keep records consistent with the indexed column i.e. id. To examine this ordering in action, execute the subsequent script:
USE schooldb
INSERT INTO student
VALUES
(6, ‘Kate’, ‘Female’, ’03-JAN-1985′, 500, ‘Liverpool’),
(2, ‘Jon’, ‘Male’, ’02-FEB-1974′, 545, ‘Manchester’),
(9, ‘Wise’, ‘Male’, ’11-NOV-1987′, 499, ‘Manchester’),
(3, ‘Sara’, ‘Female’, ’07-MAR-1988′, 600, ‘Leeds’),
(1, ‘Jolly’, ‘Female’, ’12-JUN-1989′, 500, ‘London’),
(4, ‘Laura’, ‘Female’, ’22-DEC-1981′, 400, ‘Liverpool’),
(7, ‘Joseph’, ‘Male’, ’09-APR-1982′, 643, ‘London’),
(5, ‘Alan’, ‘Male’, ’29-JUL-1993′, 500, ‘London’),
(8, ‘Mice’, ‘Male’, ’16-AUG-1974′, 543, ‘Liverpool’),
(10, ‘Elis’, ‘Female’, ’28-OCT-1990′, 400, ‘Leeds’);
The higher than script inserts 10 records within the student table. Notice here the records area unit inserted in random order of the values within the “id” column. However thanks to the default clustered index on the id column, the records area unit physically keeps within the ascending order of the values within the “id” column. Execute the subsequent choose statement to retrieve the records from the scholar table.
USE schooldb
SELECT * FROM student
The records are retrieved within the following order:
| Id | Name | Gender | DOB | Total score | city |
| 1 | Jolly | Female | 1989-06-12 00:00:00.000 | 500 | London |
| 2 | Jon | Male | 1974-02-02 00:00:00.000 | 545 | Manchester |
| 3 | Sara | Female | 1988-03-07 00:00:00.000 | 600 | Leeds |
| 4 | Laura | Female | 1981-12-22 00:00:00.000 | 400 | Liverpool |
| 5 | Alan | Male | 1993-07-29 00:00:00.000 | 500 | London |
| 6 | Kate | Female | 1985-01-03 00:00:00.000 | 500 | Liverpool |
| 7 | Joseph | Male | 1982-04-09 00:00:00.000 | 643 | London |
| 8 | Mice | Male | 1974-08-16 00:00:00.000 | 543 | Liverpool |
| 9 | Wise | Male | 1987-11-11 00:00:00.000 | 499 | Manchester |
| 10 | Elis | Female | 1990-10-28 00:00:00.000 | 400 | Leeds |
Creating Custom Clustered Index:
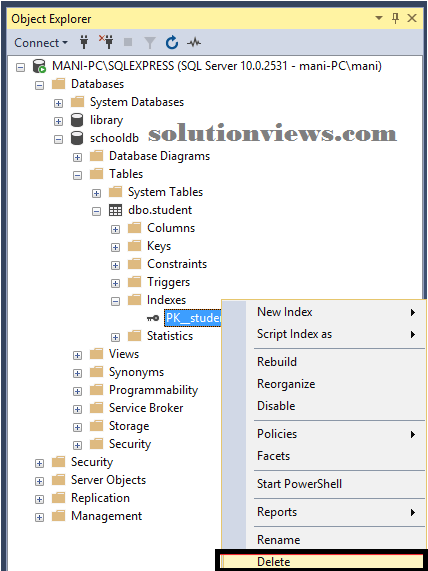
You can produce your own custom index yet the default clustered index. to form a brand new clustered index on a table you initially need to delete the previous index.
To delete Associate in Nursing index visit “Object Explorer-> Databases-> Database_Name-> Tables-> Table_Name -> Indexes”. Right click the index that you simply need to delete and choose DELETE. See the below screenshot.
Now, to form a brand new clustered Index, execute the subsequent script:
use schooldb
CREATE CLUSTERED INDEX IX_tblStudent_Gender_Score
ON student(gender ASC, total_score DESC)
The process of making clustered index is analogous to a traditional index with one exception. With clustered index, you have got to use the keyword “CLUSTERED” before “INDEX”.
The higher than script creates a clustered index named “IX_tblStudent_Gender_Score” on the scholar table. This index is made on the “gender” and “total_score” columns. Associate in nursing index that’s created on over one column is termed “composite index”.
The higher than index initial types all the records within the ascending order of the gender. If gender is same for 2 or additional records, the records area unit sorted within the degressive order of the values in their “total_score” column. you’ll be able to produce a clustered index on one column yet. currently if you choose all the records from the scholar table, they’re going to be retrieved within the following order:
| id | name | gender | DOB | Total score | city |
| 3 | Sara | Female | 1988-03-07 00:00:00.000 | 600 | Leeds |
| 1 | Jolly | Female | 1989-06-12 00:00:00.000 | 500 | London |
| 6 | Kate | Female | 1985-01-03 00:00:00.000 | 500 | Liverpool |
| 4 | Laura | Female | 1981-12-22 00:00:00.000 | 400 | Liverpool |
| 10 | Elis | Female | 1990-10-28 00:00:00.000 | 400 | Leeds |
| 7 | Joseph | Male | 1982-04-09 00:00:00.000 | 643 | London |
| 2 | Jon | Male | 1974-02-02 00:00:00.000 | 545 | Manchester |
| 8 | Mice | Male | 1974-08-16 00:00:00.000 | 543 | Liverpool |
| 5 | Alan | Male | 1993-07-29 00:00:00.000 | 500 | London |
| 9 | Wise | Male | 1987-11-11 00:00:00.000 | 499 | Manchester |
Non-Clustered Indexes:
A non-clustered index doesn’t type the physical knowledge within the table. In fact, a non-clustered index is keep at one place and table knowledge is kept in another place. this can be just like a textbook wherever the book content is found in one place and also the index is found in another. This permits for over one non-clustered index per table.
It is vital to say here that within the table the info are sorted by a clustered index. However, within the non-clustered index knowledge is keep within the specific order. The index contains column worth on that the index is made and also the address of the record that the column value belongs to.
When a question is issued against a column on that the index is made, the info can initial visit the index and appearance for the address of the corresponding row within the table. It’ll then visit that row address and fetch alternative column values. It’s because of this extra step that non-clustered indexes area unit slower than clustered indexes.
Creating a Non-Clustered Index:
The syntax for making a non-clustered index is analogous thereto of clustered index. However, just in case of non-clustered index keyword “NONCLUSTERED” is employed rather than “CLUSTERED”. Take a glance at the subsequent script.
use schooldb
CREATE NONCLUSTERED INDEX IX_tblStudent_Name
ON student(name ASC)
The higher than script creates a
non-clustered index on the “name” column of the scholar table. The index types by name in ascending order. As we have a tendency to aforesaid earlier, the
table knowledge and
index are keep in several places. The table records are sorted by a clustered index
if there’s one. The
index are sorted consistent with its definition and can be keep individually from the table.
Student Table Data:
| id | Name | gender | DOB | Total score | City |
| 1 | Jolly | Female | 1989-06-12 00:00:00.000 | 500 | London |
| 2 | Jon | Male | 1974-02-02 00:00:00.000 | 545 | Manchester |
| 3 | Sara | Female | 1988-03-07 00:00:00.000 | 600 | Leeds |
| 4 | Laura | Female | 1981-12-22 00:00:00.000 | 400 | Liverpool |
| 5 | Alan | Male | 1993-07-29 00:00:00.000 | 500 | London |
| 6 | Kate | Female | 1985-01-03 00:00:00.000 | 500 | Liverpool |
| 7 | Joseph | Male | 1982-04-09 00:00:00.000 | 643 | London |
| 8 | Mice | Male | 1974-08-16 00:00:00.000 | 543 | Liverpool |
| 9 | Wise | Male | 1987-11-11 00:00:00.000 | 499 | Manchester |
| 10 | Elis | Female | 1990-10-28 00:00:00.000 | 400 | Leeds |
IX_tblStudent_Name
Index knowledge
| name | Row Address |
| Alan | Row Address |
| Alan | Row Address |
| Jolly | Row Address |
| Jon | Row Address |
| Joseph | Row Address |
| Kate | Row Address |
| Laura | Row Address |
| Mice | Row Address |
| Sara | Row Address |
| Wise | Row Address |
Notice, here within the index each row incorporates a column that stores the address of the row to that the name belongs. thus if a question is issued to retrieve the gender and DOB of the scholar named “Jon”, the info can initial search the name “Jon” within the index. it’ll then browse the row address of “Jon” and can go on to that row within the “student” table to fetch gender and DOB of Jon.
Conclusion:
From the discussion we discover following variations between clustered and non-clustered indexes.
- There is just one clustered index per table. However, you’ll be able to produce multiple non-clustered indexes on one table.
- Clustered indexes solely type tables. Therefore, they are doing not consume additional storage. Non-clustered indexes area unit keep in a very separate place from the particular table claiming additional cupboard space.
- Clustered indexes area unit quicker than non-clustered indexes since they don’t involve any additional operation step.
